Fedora
The Fedora Repository open source software is a project supported by the DuraSpace not-for-profit organization. The software has its origins in the Flexible Extensible Digital Object Repository Architecture (i.e., Fedora) which was originally designed and developed by researchers at Cornell University. Fedora is a robust, modular, open source repository system for the management and dissemination of digital content. It is especially suited for digital libraries and archives, both for access and preservation. It is also used to provide specialized access to very large and complex digital collections of historic and cultural materials as well as scientific data. Fedora has a worldwide installed user base that includes academic and cultural heritage organizations, universities, research institutions, university libraries, national libraries, and government agencies.
Fedora's flexibility enables it to integrate gracefully with many types of enterprise and web-based systems, offering scalability (e.g., millions of objects) and durability (e.g., all of the information is maintained in files with no software dependency, from which the complete repository can be rebuilt at any time). It also provides the ability to express rich sets of relationships among digital resources and to query the repository using the semantic web's SPARQL query language.
Fedora 1.0 was released in May 2003, with subsequent releases following approximately every quarter which have added functionality and corrected defects discovered by users and the Fedora development team. The most current and supported version is Fedora 3.8 (released in June 2015), and brand new version, Fedora 4 is about to release soon. (See Fedora 4.0 Documentation here: https://wiki.duraspace.org/display/FEDORA40/Fedora+4.0+Documentation)
Fedora's architecture for complex objects and their relationships
This section relates mainly to Fedora version 2.0.
The original article (https://arxiv.org/ftp/cs/papers/0501/0501012.pdf) article was written when the actual release of Fedora was version 2.0, which includes the semantic web integration that is important for us.
Fedora's object model uniquely integrates advanced content management with semantic web technology. It supports the representation of rich information networks, where the nodes are complex digital objects combining data and metadata with web services and the edges are ontology-based relationships among these digital objects.
The most familiar example is the need to express well-known management relationships among digital resources such as the organization of items in a collection and structural relationships such as the part-whole relationships between individual articles and a journal. While the relationships among digital objects in these familiar applications are mainly hierarchical, Fedora deals with other applications where the relationships are more graph-like.
There are a number of schemes for representing these relationships such as conventional relational databases and formalisms like conceptual graphs, the products of the semantic web initiative such as RDFS, OWL, and highly scalable triple-stores provide extensible open-source solutions for representation, manipulation, and querying these knowledge networks.
By providing both a model for digital objects and repository services to manage them, Fedora is distinguished from work focused on defining and promoting standard XML formats for representing and transmitting complex objects (e.g., METS, MPEG-21 DIDL, IEEE LOM). However, Fedora is compatible with these efforts since it has the ability to ingest and export digital objects that are encoded in such XML transmission formats. This allows Fedora to comfortably coexist in the archival framework defined by OAIS (Open Archival Information System).
Fedora model for complex objects
The Fedora object model supports the expression of many kinds of complex objects, including documents, images, electronic books, multi-media learning objects, datasets, computer programs, and other compound information entities. Fedora supports aggregation of any combination of media types into complex objects, and allows the association of services with objects that produce dynamic or computed content. The Fedora model also allows the assertion of relationships among objects so that a set of related Fedora objects can represent the items in a managed collection, the components of a structural object like the chapters of a book, or a set of resources that share common characteristics (defined by semantic relationships).
Fedora defines a powerful object model for expressing this variety of complex content and their relationships. This object model can be understood from two perspectives:
The representational perspective defines a simplified abstraction for understanding Fedora objects, where each object is modeled as a uniquely identified resource projecting one or more views, or representations. From this perspective the internal structure of a digital object is opaque; however, relationships among objects are observable.
The functional perspective reveals the object components that underlie the representational perspective and provides the basis for understanding how the Fedora object model relates to the management services exposed in the Fedora repository architecture.
Representational View
The representational perspective of the Fedora object model asserts that each digital object can disseminate one or more representations of itself, and that each object can be related to one or more other objects. A familiar example of digital object with multiple representations is a document or image where the content is available in multiple formats. All digital objects, and their individual representations, are identified with Uniform Resource Identifiers (URIs). This choice frees the architecture from ties with any identifier resolution system (e.g., the Handle System).
This perspective hides complexity and exposes only the access points to content stored in a Fedora repository. The figure below depicts the representational view of three inter-related Fedora objects. The diagram shows a directed graph, where the larger nodes are digital objects, and the smaller nodes are representations of the digital objects. These nodes are linked by two types of arcs – relationship arcs connect digital objects, and representation arcs connect digital objects to their respective representations. This graph can be expressed as RDF, stored in a triple store, and queried.

Each digital object in the diagram has at least one representation, related to its originating digital object by a “hasRep” arc. For example, the node labeled info:fedora/demo:11 is an image digital object with four representations, identified by
their respective URIs:
Dublin Core record, identified as
info:fedora/demo:11/DCHigh-resolution image, identified as
info:fedora/demo:11/HIGHThumbnail image, identified as
info:fedora/demo:11/THUMBImage with zoom/pan utility, as
info:fedora/demo:11/bdef:2/ZPAN
This figure also demonstrates an example of inter-object relationships. In this example, the node labeled info:fedora/demo:10 is a “collection” with two “items”, the nodes labeled info:fedora/demo:11 and info:fedora/demo:12. These collection-item
relationships are expressed by the “hasMember“ arc that emanates from the collection object. The inverse “isMemberOf” relationships are not shown in the diagram for simplification.
This simple representational view forms the basis of Fedora’s REST-based access service (i.e., API-A-LITE), whereby digital object URIs and representation URIs can be easily converted to service request URLs upon Fedora repositories.
Functional View I - Datastreams
While the representational perspective of the Fedora object model provides a simple, access-oriented overlay for digital resources and collections, the functional perspective provides a view of the core underlying data model for Fedora.
In its simplest form a Fedora object is an aggregation of content items, where each content item maps to a representation. The Fedora object model defines a component known as a datastream to represent a content item. A datastream component either encapsulates bytestream content internally or references it externally. In either case that content may be in any media type.
The figure below shows the digital object (info:fedora/ demo:11) as an aggregation of datastreams and the one-to-one correspondence of those datastreams to the representations of the digital object that are exposed to accessing clients. In this simple case, each representation of a Fedora object is a simple transcription of the content that lies behind a datastream component.

As seen in the above diagram, a digital object has a unique identifier (PID) and a set of key descriptive properties. Each datastream contains information necessary to manage a content item in a Fedora repository. These are stored as properties of the datastream as shown in the figure below.

Three datastream properties deserve special attention. The FORMAT_URI refines the media type definition and anticipates the emergence of a global digital format registry such as the GDFR. CONTROL_GROUP defines whether the datastream represents either local or remote content. Datastreams with a control group of “Managed” are internal content bytestreams that are under the direct custodianship of the Fedora repository. Datastreams whose control group is “External” or “Redirected” represent content that is stored outside the repository. These datastreams have a CONTENT_LOCAT property that is a URL pointing to a service point outside the repository that is responsible for providing the content. The ability to create digital objects that aggregate locally managed content with external content is a powerful feature of Fedora, and is useful in a variety of contexts. A good example of a hybrid local/remote object is an educational object where local content is an instructor’s syllabus, lecture notes, and exams, and remote content are primary resources included by-reference from other sites.
Functional View II - Disseminators
In addition to the representations described in the previous section, which are direct transcriptions of datastreams, the Fedora object model enables the definition of virtual representations of a digital object. A virtual representation, also known as a dissemination, is a view of an object that is produced by a service operation (i.e., a method invocation) that can take as input one or more of the datastreams of the respective digital object. As such, it is a means to deliver dynamic or computed content from a Fedora object.
This is illustrated in the figure below, where a virtual representation labeled info:fedora/demo:11/BDEF:2/ZPAN is highlighted. From the access perspective this representation is an image wrapped in a java application that provides image zoom and pan functions. Note that this representation is not a direct transcription of any datastream in the object. Instead, it is the result of a service operation defined in the Disseminator component labeled “BDEF:2” inside the object that uses the datastream labeled “HIGH” as input. The light-weight, REST-based interface to Fedora (API-ALITE) makes it possible for a client application to pass parameters to the invoked service; in this case zoom and pan specifications.

To enable such behavior, a Disseminator must contain three pieces of information: (1) a reference to a description of service operation(s) in an abstract syntax, (2) a reference to a WSDL service description that defines bindings to concrete web service to run operation(s), and (3) the identifiers of any Datastreams in the object that should be used as input to the service operation(s).
Fedora stores the service operation description and the WSDL service description within special digital objects, respectively known as BDefs (behavior definitions) and BMechs (behavior mechanisms). The figure below depicts a Fedora BDef object and a BMech object along with object-to-object relationships that exist due to the presence of the Disseminator component in the main object (i.e., demo:11).

Disseminators are effectively metadata that a Fedora repository uses at run time to construct and dispatch service requests and produce one or more virtual representations of the digital object. From a client perspective this is transparent since virtual representations look just like other representations of the object.
Disseminators are a powerful feature in the Fedora object model. They can be used to create common representational access points for digital objects that have different underlying structure or format. For example, an institutional repository might contain scholarly documents in a variety of root formats (e.g., Word, HTML, TeX), where the root format is stored as a datastream in a Fedora digital object. For interoperability purposes, a virtual representation can be defined on each object that converts the datastream containing the root format to a common format (e.g., PDF). Similarly, a repository manager can decide for archival purposes to convert all documents in a repository to a canonical preservation format without disrupting the manner in which clients access documents for browsing, viewing, etc. Finally, disseminators can add utility operations to digital objects. For example, a Disseminator can be defined for a digital object that provides parameterized query access to the relationships defined for that object. Such a query might return the “members of a collection” or, in the case of an educational digital library such as the NSDL (National Science, Technology, Engineering, and Mathematics Education Digital Library), the set of resources that are appropriate for K-12 mathematics education.
Functional View III – Object Integrity Components
The Fedora object model defines several metadata entities that pertain to managing the integrity of digital objects. These entities are the object’s relationship metadata, access control policy, and audit trail. To keep the Fedora model simple and consistent, integrity entities are modeled as datastream components with reserved identifiers. As such, the integrity entities are stored like other datastreams, however the Fedora Repository system recognizes them as special and asserts constraints over how they are created and modified. The figure below depicts these integrity-oriented entities as special datastreams in a digital object, identified as Relations, Policy, and Audit Trail.

A Relations datastream is used to assert object-to-object relationships such as collection/member, part/whole, equivalence, “aboutness,” and more. The previously discussed “hasMember” relationship is an example of the type of assertion that can be managed via the Relations datastream.
A Policy datastream is used to express authorization policies for digital objects, both to protect the integrity of an object and to enable fine-grained access controls on an object’s content. In Fedora objects, a policy is expressed using the eXtensible Access Control Markup Language (XACML), which is a flexible XML-based language used to assert statements about who can do what with an object, and when they can do it. Object policies are enforced by the authorization module (i.e., AuthZ) implemented within the Fedora repository service.
The Audit Trail is a system-controlled datastream that keeps a record of all changes to an object during its lifetime. The Fedora repository service automatically creates an audit record for every operation upon an object, detailing who, what, when, where, and why an object was changed. This information is important to support preservation and archiving of digital objects.
Another feature for managing the lifecycle of objects is versioning. Versioning is important for applications where change tracking is essential, as well as for preservation and archiving systems that must be able to recover historical views of digital objects. The Fedora object model supports component-level versioning, meaning that datastreams and disseminators can be changed without losing their former instantiations. Fedora automatically creates a new version of these components whenever they are modified.
This is depicted in the figure above, which shows a digital object with multiple versions of a datastream (see component labeled “HIGH”). Also, the versioned datastream is input to the disseminator labeled “BDEF:2.” Requests for representations of this digital object can be date-time stamped and the Fedora repository service will ensure that the appropriate component version is returned. This feature applies for representations that are direct transcriptions of datastream content, as well as for virtual representation where datastream content is mediated via a Disseminator.
Relationships in Fedora
The Fedora object model can be abstractly viewed as a directed graph, consisting of internal arcs that relate digital objects nodes to their representation nodes and external arcs between digital objects.
The Fedora Resource Index module allows storage and query of the graph. This module builds on RDF (Resource Description Framework) primitives. The Fedora system defines a base relationship ontology that, in the fashion of any RDF properties, can co-exist with domain-specific ontologies from other namespaces. Each digital object’s relationships to other digital objects are expressed in RDF/XML within a reserved datastream in the object. The Resource Index is a relationship graph over all digital objects in the repository that is derived by merging the relationships implied by the Fedora object model itself with the relationships explicitly stated in an object’s relationship datastream. The triples representing this graph are then stored in a triple-store providing the capability for searching over the graph.
The combination of representing explicit relationships as RDF/XML in a datastream of a digital object and then mapping them to the Kowari triple store offers the “best of both worlds”. The explicit representation provides the basis for exporting, transporting, and archiving of the digital objects with their asserted relationships to other objects. The mapping to (Kowari) triples provides a graph-based index of an entire repository and the basis for high-performance queries over the relationships. An added advantage of the dual representation is that the entire triple store can be rebuilt by importing and parsing the XML-based digital objects.
Representing object-to-object relationships
Fedora decomposes the structural units (e.g. book composed of chapters and diaries consisting of entries) into separate digital objects. The units can then be reused in a variety of structural compositions. In addition, this lays the basis for expressing other types of non-structural relationships among digital objects such as:
- The organization of individual resources into larger collection units, for the purpose of management, (OAI-PMH) harvesting, user browsing, and other uses.
- The relationships among bibliographic entities.
- Semantic relationships among resources such as their relevance to state educational standards or curricula in an educational digital library like the National Science Digital Library.
- Modeling more complex forms of network overlays over the resources in a content repository such as citation links, link structure, friend of a friend, etc.
All of these relationships, including structural relationships, should be expressible both within individual digital objects and among multiple digital objects. For example breaking the components of a structural entity, such as the chapters of a book, into separate digital objects provides the flexibility for reuse of those individual components into other structural units. This is even more important for the other forms of relationships. For example, a single resource may be part of multiple collections or may be relevant for multiple state standards.
The expression of arbitrary, inter-object relationships in Fedora is enabled by a reserved datastream known as the Relations datastream. This datastream allows for a restricted subset of RDF/XML where the subject of each statement must be the digital object within which the datastream is defined.
Since predicates from any vocabulary can be used in Relations, the repository manager has considerable flexibility in the kinds of relationships that can be asserted. The code segment below shows an example Relations datastream in a Fedora digital object identified by the URI, info:fedora/demo:11. The RDF/XML refers to three different relationship
vocabularies (hypothetical for the purpose of this example) and asserts the following
relationships:
• demo:11 is a member of the collection represented by the object demo:10,
• demo:11 fulfills the state educational standard represented by the object demo:Standard5,
• demo:11 is a manifestation of the expression represented by the object demo:Expression2.
<rdf:RDF
xmlns:rdf ="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:nsdl=”http://nsdl.org/std#”
xmlns:rel="http://example.org/rel#"
xmlns:frbr="http://example.org/frbr#">
<rdf:Description rdf:about="info:fedora/demo:11">
<rel:isMemberOf rdf:resource="info:fedora/demo:10"/>
<std:fulfillsStandard rdf:resource="info:fedora/demo:Standard5"/>
<frbr:isManifestionOf rdf:resource=
"info:fedora/demo:Expression2"/>
</rdf:Description>
</rdf:RDF>
Object representations and properties in the Resource Index
A Fedora digital object consists of a number of core components such as datastreams and disseminators, which bind to BDefs and BMechs. In addition each Fedora digital object has system metadata or properties. The architecture provides a system-defined ontology to represent the relationships among these core components. For example, the relationships of an object to its representations is expressed using the <fedora-model:disseminates predicate as shown in the triple below:
<info:fedora/demo:11>
<fedora-model:disseminates>
<info:fedora/demo:11/HIGH>
In addition to these relationships, the system-defined ontology also represents object data properties whose range contains date and boolean datatypes, as shown in the triple below:
<info:fedora/demo:11/HIGH>
<fedora-view:lastModifiedDate>
"2004-12-12T00:22:00"^^xsd:dateTime
Unlike the relationships expressed in the Relations datastream, these relationships are not explicitly asserted within the digital object. Instead they are derived from the structure of the object itself and mapped into the Resource Index, alongside the relationships represented in the Relations datastreams.
Storing and querying the relationship graph
All these relationships – the relationships explicitly stated in the Relations datastream, the relationships implied by the object structure, and the data relationships contained in the object properties – are stored in the Resource Index. This index is automatically updated by the repository service whenever an object structure is modified or its Relations datastream is changed.
The Resource Index handles queries over these relationships. The combination of all relationships into a single graph, and the automated management of that combined graph, enables a powerful and flexible service model. External services may issue queries combining relationships from different name spaces, since they are all RDF properties. The example below shows a query listing all the representations of all objects that are members of a particular collection.
select $dissemination
from <#ri>
where ($object <fedora-view:disseminates> $dissemination)
and $object <rel:isMemberOf> <demo:10>
An early design goal of the Resource Index was to allow the use of different triplestores and thus permit the Fedora repository administrator to choose the most appropriate underlying store. To that end, the Resource Index employs a triplestore API similar in spirit to JDBC, to provide a consistent update and query interface to a variety of triplestores. Extensive testing of both query performance time and query language features ultimately led to the selection of Kowari as the default triplestore.
The RDF query results naturally take the form of rows of key-value pairs, again similar to the result sets returned by a SQL query. However, it is often useful to work with a sub-graph or a constructed graph based on the original. To this end, the query API may also return triples instead of tuples.
Using the relationship graph
The Resource Index interface is exposed in a REST architectural style to provide a stateless query interface that accepts queries by value or by reference. The service has been implemented with an eye toward eventual conformance to the W3C Data Access Working Group's SPARQL protocol for RDF, as it matures.
One example of a service exploiting the Resource Index is the OAI Provider Service that exposes metadata about resources in a Fedora repository. This OAI Provider Service is quite flexible in that it can be configured to allow harvesting not only of static metadata formats, but those that are dynamically produced via service-based disseminations of Fedora objects.
An example of the interaction of this service with the Resource Index is as follows. An external OAI harvester requests qualified Dublin Core records for a particular set of resources from the repository. The OAI Provider service processes this by issuing the query to the Resource Index listed below. This query effectively requests “all disseminations of qualified Dublin Core records of resources that are members of the collection identified as demo:10”. The significance of requesting disseminations is that the Dublin Core records may not statically exist as datastreams within the object, but they may be derived from another metadata format such as MARC.
select $member $collection $dissemination
from <#ri>
where $member <rel:isMemberOf> <info:fedora/demo:10>
and $member <rel:isMemberOf> $collection
and $member <rel:isMemberOf> $dissemination
and $member <fedora-view:disseminates> $dissemination
and $dissemination <fedora-view:disseminationType>
<info:fedora/*/bdef:OAI/getQualifiedDC>
The Resource Index query would return the tuples shown below that can provide the basis of an OAI response.
| member | collection | dissemination |
|---|---|---|
| info:fedora/demo:11 | info:fedora/demo:10 | info:fedora/demo:11/bdef:OAI/getDC |
| info:fedora/demo:12 | info:fedora/demo:10 | info:fedora/demo:12/bdef:OAI/getDC |
Application in National Science Digital Library
The NSDL (National Science Digital Library) Project is perhaps the most interesting example of the power of Fedora’s relationship architecture. The goal in the NSDL is not only to provide a digital library allowing search and access to distributed resources, but to augment NSDL resources with context that defines their usability and reusability in different learning and teaching environments. By “context”, we mean information such as the provenance of the resources, the manner in which resources have been used, comments by users that annotate and explain primary resources, and linkages between the resources and relevant state educational standards. While the NSDL work is specifically targeted at the education domain, we argue that the notion of contextualization is increasingly important as a means of adding value to digital content and defining its quality based on provenance, utility, and other factors.
Using the content management and semantic web tools in Fedora an information network overlay has been implemented. This architecture represents the data underlying the NSDL as a graph of typed nodes, corresponding to the information entities in the NSDL, and semantic edges representing the contextual relationships among those entities. The nature and variety of these relationships will evolve over time and, thus, any fixed schema approach for representing the network overlay would be too restrictive. The results thus far indicate that the semantic web approach of Fedora is particularly well-suited for this application.
The figure below illustrates a fragment of the network overlay. The nodes in the overlay graph correspond to Fedora digital objects – each shape corresponding to an information entity in the NSDL. These entities include agents, resources, metadata, and the like. The edges are relationships among these entities, which are represented in the Resource Index. For example, the figure below shows the grouping of resources in collections, and the provenance trail of who originally recommended those resources and who manages them. Relationships from other ontologies, such as state education standards, are overlaid on this base graph. These are similarly represented in the Resource Index alongside the base ontology relationships. The entire knowledge base can then be queried by external services to build rich portals for users and tools for inferring quality, usability, and educational value.
 fgfggf
fgfggf
Digital Object Model in Fedora
This section relates mainly to Fedora version 3.8.
Fedora defines a generic digital object model that can be used to persist and deliver the essential characteristics for many kinds of digital content including documents, images, electronic books, multimedia learning objects, datasets, metadata and many others. This digital object model is a fundamental building block of the Content Model Architecture (CMA) and all other Fedora-provided functionality.
Fedora uses a "compound digital object" design which aggregates one or more content items into the same digital object. Content items can be of any format and can either be stored locally in the repository, or stored externally and just referenced by the digital object. The Fedora digital object model is simple and flexible so that many different kinds of digital objects can be created, yet the generic nature of the Fedora digital object allows all objects to be managed in a consistent manner in a Fedora repository.
The Fedora digital object model is defined in XML schema language (see The Fedora Object XML - FOXML).
The basic components of a Fedora digital object are:
- PID: A persistent, unique identifier for the object.
- Object Properties: A set of system-defined descriptive properties that are necessary to manage and track the object in the repository.
- Datastream(s): The element in a Fedora digital object that represents a content item.
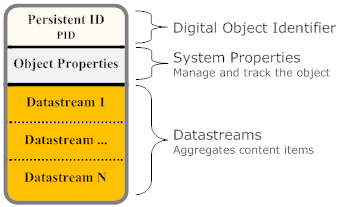
Datastreams
A datastream is the element of a Fedora digital object that represents a content item. A Fedora digital object can have one or more datastreams. Each datastream records useful attributes about the content it represents such as the MIME-type (for Web compatibility) and, optionally, the URI identifying the content's format (from a format registry). The content represented by a datastream is treated as an opaque bit stream; it is up to the user to determine how to interpret the content (i.e. data or metadata). The content can either be stored internally in the Fedora repository, or stored remotely (in which case Fedora holds a pointer to the content in the form of a URL).
Each datastream is given a Datastream Identifier which is unique within the digital object's scope. Fedora reserves four Datastream Identifiers for its use, "DC", "AUDIT", "RELS-EXT" and "RELS-INT". Every Fedora digital object has one "DC" (Dublin Core) datastream by default which is used to contain metadata about the object (and will be created automatically if one is not provided). Fedora also maintains a special datastream, "AUDIT", that records an audit trail of all changes made to the object, and can not be edited since only the system controls it. The "RELS-EXT" datastream is primarily used to provide a consistent place to describe relationships to other digital objects, and the "RELS-INT" datastream is used to describe internal relationships from digital object datastreams. In addition, a Fedora digital object may contain any number of custom datastreams to represent user-defined content.

The basic properties that the Fedora object model defines for a datastream are as follows:
- Datastream Identifier: an identifier for the datastream that is unique within the digital object (but not necessarily globally unique)
- State: the datastream's state: Active, Inactive, or Deleted
- Created Date: the date/time that the datastream was created (assigned by the repository service)
- Modified Date: the date/time that the datastream was modified (assigned by the repository service)
- Versionable: an indicator (true/false) as to whether the repository service should version the datastream (by default the repository versions all datastreams)
- Label: a descriptive label for the datastream
- MIME Type: the MIME type of the datastream (required)
- Format Identifier: an optional format identifier for the datastream such as emerging schemes like PRONOM (a web-based technical registry to support digital preservation services, developed by The National Archives of the United Kingdom) and the Global Digital Format Registry (GDRF)
- Alternate Identifiers: one or more alternate identifiers for the datastream (such identifiers could be local identifiers or global identifiers such as Handles or DOI)
- Checksum: an integrity stamp for the datastream content which can be calculated using one of many standard algorithms (MD5, SHA-1, etc.)
- Bytestream Content: the content (as a stream resource) represented or encapsulated by the datastream (such as a document, digital image, video, metadata record)
- Control Group: the approach used by the datastream to represent or encapsulate the content as one of four types or control groups (Internal XML Content, Managed Content, Externally Referenced Content, Redirect Referenced Content)
Four Types of Fedora Digital Objects
Although every Fedora digital object conforms to the Fedora object model, as described above, there are four distinct types of Fedora digital objects that can be stored in a Fedora repository. The distinction between these four types is fundamental to how the Fedora repository system works. In Fedora, there are objects that store digital content entities, objects that store service descriptions, objects used to deploy services, and objects used to organize other objects.
Data Object
In Fedora, a Data object is the type of object used to represent a digital content entity. Data objects are what we normally think of when we imagine a repository storing digital collections. Data objects can represent such varied entities as images, books, electronic texts, learning objects, publications, datasets, and many other entities. One or more datastreams are used to represent the parts of the digital content. A Datastream is an XML element that describes the raw content (a bitstream or external content).
Service Definition Object
In Fedora, a Service Definition object or SDef is a special type of control object used to store a model of a Service. A Service contains an integrated set of Operations that a Data object supports. In object-oriented programming terms, the SDef defines an "interface" which lists the operations that are supported but does not define exactly how each operation is performed. This is also similar to approaches used in Web (REST) programming and in SOAP Web services.
Service Deployment Object
The Service Deployment object or SDep is a special type of control object that describes how a specific repository will deliver the Service Operations described in a SDef for a class of Data objects described in a CModel (see below). The SDep is not executable code but instead it contains information that tells the Fedora repository how and where to execute the function that the SDep represents.
Content Model Object
The Content Model object or CModel is a new specialized control object introduced as part of the CMA. It acts as a container for the Content Model document which is a formal model that characterizes a class of digital objects. It can also provide a model of the relationships which are permitted, excluded, or required between groups of digital objects. All digital objects in Fedora including Data, SDef, SDep, and CModelobjects are organized into classes by the CModelobject.
Common metadata design patterns in Fedora
This section relates mainly to Fedora version 4.
Fedora 4 presents metadata designers with radical new capabilities, as well as new responsibilities.
Ordering
RDF, as a graph, is inherently unordered, and this can lead to difficulty when forms of description that presuppose ordering are translated into it. The Fedora community is trying several methods for constructing order in a graph.
The choice of how to represent ordering is up to the user. In the following example there is an ordered list of authors for an academic research paper. Generally the authors of these papers care about the order they are cited, and so in this scenario we must retain their ordering.
One might be tempted to use a structure that relies on RDF "blank nodes", such as most tools generate by default from the Collection notation in RDF Turtle. As mentioned in Common metadata design patterns, blank nodes are not well-defined in the repository context and should generally not be used in Fedora. So here's an example of what to avoid:
@prefix dc: <http://purl.org/dc/elements/1.1/> .
<>
dc:title "Important Academic Research Paper" ;
# Avoid the following
dc:creator (<http://example.com/author/Quinn> #no
<http://example.com/author/Alice> #no
<http://example.com/author/Bob>) . #no
That example creates a bunch of blank nodes, which then get mangled going into Fedora. Let's not do that. Here's a very simple alternative formation that gets the job done. Use hash-URIs instead of blank nodes.
@prefix dc: <http://purl.org/dc/elements/1.1/> .
@prefix owl: <http://www.w3.org/2002/07/owl#> .
<>
dc:title "Test title" ;
dc:creator <#author_1>, <#author_2>, <#author_3> .
<#author_1> owl:sameAs <http://example.com/author/Quinn> .
<#author_2> owl:sameAs <http://example.com/author/Alice> .
<#author_3> owl:sameAs <http://example.com/author/Bob> .
In addition to being Fedora-friendly, this formulation is arguably better from a representational standpoint: anybody iterating the triples can query for the paper by author without having to jump through rdf:list hijinx. Of course, those consumers that care about the ordering would need to parse the number out of the hash part of each URI and sort by that. For plenty of people that's good enough.
Paired values
Missing from the documentation
Date and time ranges
Missing from the documentation
t.b.c.